Big Data is one of the most important topic in the last year, the world of integration has changed since the companies start providing the possibility to store our information in the Cloud.
Send the data from our on premise to a database in the cloud can be achieved in different ways, I’m very keen and focused to implement feature in GrabCaster able to solve integration problems in easy way.
GrabCaster is an open source framework and it can be used in every integration project within any environment type, no matter which technologies, transport protocols or data formats are used.
The framework is enterprise ready and it implements all the Enterprise Integration Patterns (EIPs) and offer a consistent model and messaging architecture to integrate several technologies., the internal engine offers all the required features to realize a consistent solution.
The framework can be hosted in Azure Service Fabric which enables us to build and manage scalable and reliable points running at very high density on a shared pool of machines.
Azure Service Fabric servers as the foundation for building next generation cloud and on premise applications and services of unprecedented scale and reliability, for more information about Microsoft Azure Service Fabric check here
Using GrabCaster and the Microsoft Azure stacks I’m able to execute a SQL Server Bulk Insert operation across on premise and the cloud very easily, below how it works.
I’m not going in detail, you can find all the samples and templates in the GrabCaster site.
Download GrabCaster Framework and configure it to use the Azure Redis Cache, this is one of the last messaging provider implemented, what I love about this Azure stack is the pricing and the different options offered by this framework.
Using the SQL Bulk Trigger and Event I’m able to send a large amount of data across the cloud, the engine compacts the stream and it uses the Blobs to move the large amount of records.
Last the I did was moving one million record from a table in an on premise SQL database and another in the cloud.
I installed GrabCaster in Azure Fabric as below.

I configured the SQL bulk trigger in the on premise environment using the json configuration file.
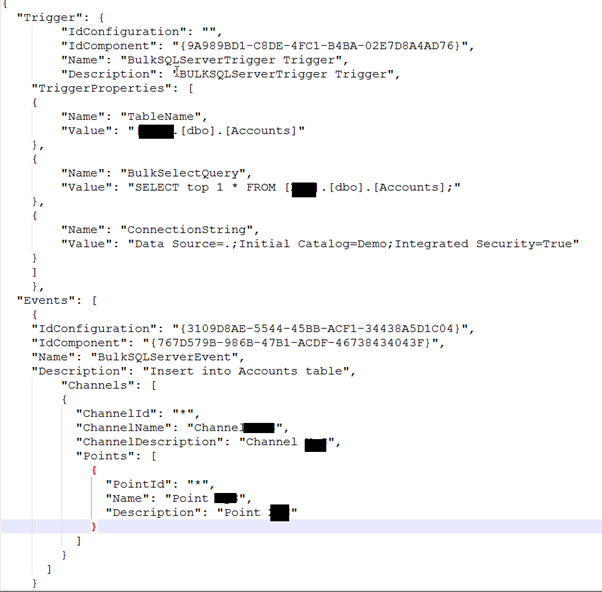
I configured the SQL Bulk event and I sent the configuration to the GrabCaster point in the Azure Fabric using the internal synchronization channel.

I can activate the GrabCaster trigger in different ways, in this case I used the REST API invocation as below.

The trigger is executed and I moved one million records from an on premise SQL Server database into a SQL Server database table in the cloud.
After tested the REST API the developer implemented a simple REST call in a Web UI button.
Below the scenario implemented.

There are some important aspects which I appreciate in this approach.
- Thank to Microsoft Azure Fabric the solution is always-on, scalable and distributed.
- The simplicity into the approach and the configuration.
- The extensibility using the REST API call to invocate the trigger.
- The using of Redis Cache and Blob which have a very low pricing consume in Microsoft Azure.